Stop Babysitting Your Agent Swarms: The One-Time Setup That Heals a Stalled Workflow
Greg Heffner June 26th, 2026
You kicked off a twelve-agent run, walked away for coffee, and came back to a progress tree that has not moved in twenty minutes. One box still spinning, nothing errored, nothing finished. So you kill it, start over, and watch the token meter climb a second time to pay for work that half those agents already did. That second bill is the most expensive thing about running agent swarms, and almost none of it is necessary.
So I did something recursive: I pointed a multi-agent workflow at the question of why multi-agent workflows stall, then handed one agent my own answer and told it to tear it apart. The fix that survived was smaller than the one I started with, and that was the lesson. You do not harden a swarm by adding machinery. You harden it by leaning on what the orchestration layer already does, and adding the few things it does not.
What you already get for free
Most of the stall-proofing people write by hand is already built in, and the dynamic workflows runtime spells out the parts that matter. You get per-item fault containment, so one bad item drops out and the rest keep flowing. A dead agent comes back as a null instead of crashing the run. Concurrency is capped, so you cannot summon a thousand agents at once. Structured output self-heals when an agent returns the wrong shape. And a run resumes: relaunch it and every unchanged step replays from cache, so only new work costs anything. Rebuild any of that by hand and you usually end up fighting it.
The six rules worth adding
Two words trip people up, so in plain terms: parallel means the run waits for every agent in a batch to finish before it moves on, and pipeline means each item moves ahead on its own without waiting for the others. With that settled, here are the six rules, each one closing a specific way runs die:
- Use a pipeline, not parallel, when the items do not depend on each other. In a parallel batch, one stuck agent freezes all of them, like a whole crowd waiting at a single gate. In a pipeline, a stuck item only holds itself up while the rest sail past.
- When agents die, say so out loud. Drop the dead ones, but hand back the tally: how many succeeded, how many failed, how many never ran. Otherwise you ship a result that looks complete and quietly is not.
- Check the token budget before each batch. If you are running low, switch to a cheaper model to finish, instead of letting the run hit its ceiling and crash partway through.
- Give every "keep going until done" loop a hard stop. If the agents keep turning up new work, the loop never ends. Cap it at a maximum number of rounds and report anything left over.
- Keep the run repeatable so it can resume. A crashed run can only pick up where it left off if every step would run the same way again. Random numbers and clock reads break that, so leave them out, and add any new work at the end so the earlier steps still line up.
- Match the model to the job. A cheap, fast model for grunt work; the strong, expensive one only for real judgment calls. Give agents their own workspace when several write files at the same time.
Rules three through five are most of the actual code. A budgeted, bounded, deterministic spawn loop is about ten lines:
const RESERVE = 0.05 * (budget.total || 1); // headroom for the next wave
let work = seed, done = [];
for (let wave = 0; wave < MAX_WAVES; wave++) { // rule 4: a hard ceiling
if (budget.total && budget.remaining() < RESERVE) break; // rule 3: budget guard
const out = (await pipeline(work.slice(0, 16), ...stages))
.filter(Boolean); // drop the dead agents
done.push(...out);
work = work.slice(16).concat(discoverMore(out)); // new work goes to the END (rule 5)
if (!work.length) break;
}
return { results: done, dropped: seed.length - done.length }; // rule 2: fail loud in the return
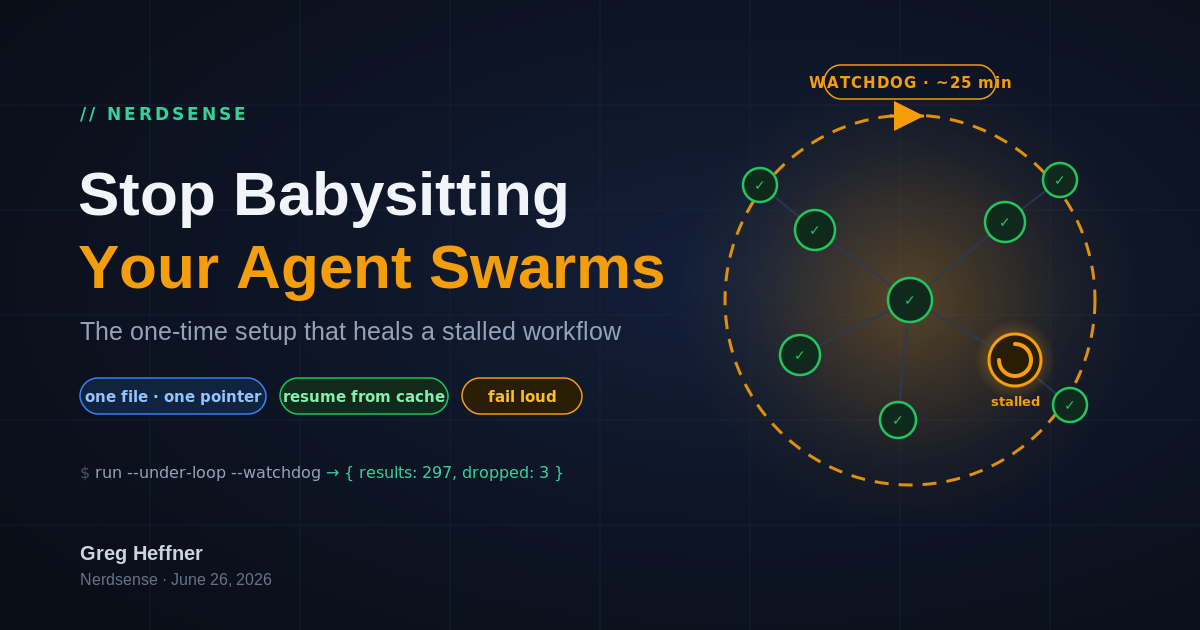
The part everyone gets wrong: the watchdog
A workflow you launch directly runs in the background and pings you when it finishes. It has no heartbeat. If it wedges in the middle, nothing notices, because the thing that wedged is the thing that would have to notice. So the watchdog has to live one level up: wrap the launch in a loop with a long fallback timer (I use about twenty-five minutes, never five, since the cache only stays warm that long), and the loop wakes on its own, sees the run is stuck, and relaunches it with resume. Resume only works within the same session and only if you kept rule five, but when it holds it turns a dead twenty-minute run into a thirty-second catch-up.
The watchdog is not a timer inside your script. It is the loop around your script.
The whole setup is one file and one line
I did not want to retype any of this. The six rules and the watchdog note live in one file,
~/.claude/resilience-preamble.md, and a single line in my standing instructions points at
it:
For any multi-agent Workflow, apply ~/.claude/resilience-preamble.md.
After that, starting a resilient run is one sentence: build this per that file, and run it under a loop with a watchdog. That is the whole ritual, and I never turned it into a thirteenth standing rule I would have to remember to obey.
Set it up once: one file, one pointer line, one loop. After that, resilience is a sentence at the top of a request, not something you sit at your desk to babysit.
What it looks like in use
Say I want to audit three hundred Terraform files for missing owner tags. The whole interaction is one sentence:
Audit every .tf file under infra/ for missing owner tags. Build it as a resilient workflow per ~/.claude/resilience-preamble.md, and run it under a loop with a watchdog.
The run fans the files out in waves of sixteen, each wave a pipeline so a slow file never blocks the
others. Around file one hundred eighty an agent wedges on a giant module and the run goes quiet.
Twenty-five minutes later the loop wakes up, sees nothing finished, and relaunches with resume: the
files that already passed come back from cache for free, and it carries on from where it died. I never
touched it. It ends by handing back { results: 297, dropped: 3 }, and because rule two put
that dropped count in the return value, I know to eyeball those three files by hand instead of
assuming all three hundred came back clean.
What it still will not fix
It is not a silver bullet, and the honest edges are worth naming. A timeout cannot interrupt a synchronous hot loop; only the watchdog one level up can. Moving on from a hung agent does not cancel it, so it keeps holding its slot until it really dies. And a budget that runs out mid-wave gives you a partial result, not a clean stop. None of those are reasons to skip the setup. They are the reason to trust the loop around your script and not a timer inside it, which is exactly why the smaller recipe beat the bigger one.
About Me
I served in the U.S. Army, specializing in Network Switching Systems and was attached to a Patriot Missile System Battalion. After my deployment and Honorable discharge, I went to college in Jacksonville, FL for Computer Science. I have two beautiful and very intelligent daughters. I have more than 20 years professional IT experience. This page is made to learn and have fun. If its messed up, let me know. Im still learning :)
Recent Blogs
Popular Projects
Book Board
Weather Loop